ຫ່າງຫາຍໄປດົນສົມຄວນ, ດຽວມື້ນີ້ຈະຂຽນເລື່ອງເບື້ອງເລິກເບື້ອງຫຼັງຂອງພາສາ JavaScript ໃຫ້ອ່ານເພື່ອເປັນພື້ນຖານໃນການນຳໃຊ້ພາສາ JavaScript ໃຫ້ມີປະສິດທິພາບ(ຫຼືບໍ່?).
Hey JS ♻️!
JS ເປັນພາສາທີ່ເຮັດວຽກແບບ **single-threaded** ແລະ **non-blocking** ໝາຍຄວາມວ່າມັນຈະເຮັດວຽກພຽງແຕ່ 1 task ຕໍ່ຄັ້ງ, ເບິ່ງຄືວ່າມັນກໍ່ບໍ່ມີບັນຫາຫຍັງ ແຕ່ລອງຄິດພາບເບິ່ງວ່າເຮົາມີ task ທີ່ຕ້ອງ process ໂດຍໃຊ້ເວລາທັງໝົດ 30 ວິນາທີ. ໃນຂະນະທີ່ task ຍັງເຮັດວຽກບໍ່ແລ້ວເທື່ອ, ແຕ່ເຮົາຕ້ອງມານັ່ງຖ້າ 30 ວິນາທີກ່ອນທີ່ຈະເກີດເຫດການອື່ນໆຕໍ່ (JS ຈະ run ຢູ່ເທິງ main thread ຂອງ browser by default ຢູ່ແລ້ວ, ດັ່ງນັ້ນ UI ທຸກຢ່າງຈະຍັງຄ້າງຢູ່ແບບນັ້ນ)😖 ແລ້ວໃຜຊິມານັ່ງຖ້າເວັບຊ້າໆແບບນັ້ນລ່ະ? ນີ້ມັນ 2023 ແລ້ວໃດ🤣🤣🤣
ໂຊກດີແນ່ທີ່ browser ມີບາງ features ທີ່ JavaScript engine ບໍ່ມີມາໃຫ້ເຊັ່ນ: Web API — ໃນນີ້ປະກອບມີ DOM API, setTimeout, HTTP requests ເປັນຕົ້ນ, ເຊິ່ງມັນເຮັດໃຫ້ເຮົາສາມາດຂຽນແບບ async, non-blocking ໄດ້.
ເມື່ອເຮົາເອີ້ນໃຊ້ function ໃດໆກໍ່ຕາມ, ສິ່ງທຳອິດທີ່ມັນເຮັດກໍ່ຄືມັນຈະ added ເຂົ້າໄປໃນ `call stack`. `call stack` ເປັນສ່ວນໜຶ່ງຂອງ JS engine ແລະ ມັນບໍ່ໄດ້ເປັນສິ່ງທີ່ມີສະເພາະ browser — ໝາຍຄວາມວ່າມັນເປັນ stack ລັກສະນະການເຮັດວຽກຂອງມັນກໍ່ຈະເປັນແບບ first in, last out (ຄິດພາບຈານໃສ່ເຂົ້າທີ່ກອງກັນເປັນຊັ້ນໆ ເມື່ອເຮົາຈະໃຊ້ຈານເຫຼົ່ານັ້ນແມ່ນເຮົາຈະທຳການຢິບເອົາຈາກອັນທີ່ຢູ່ເທິງສຸດກ່ອນ)🥞 ແລະ ເມື່ອ function ທີ່ເຮົາເອີ້ນໃຊ້ທຳການ return value ຫຼື ເຮັດວຽກສຳເລັດແລ້ວ ມັນຈະຖືກ popped ອອກໄປຈາກ stack.
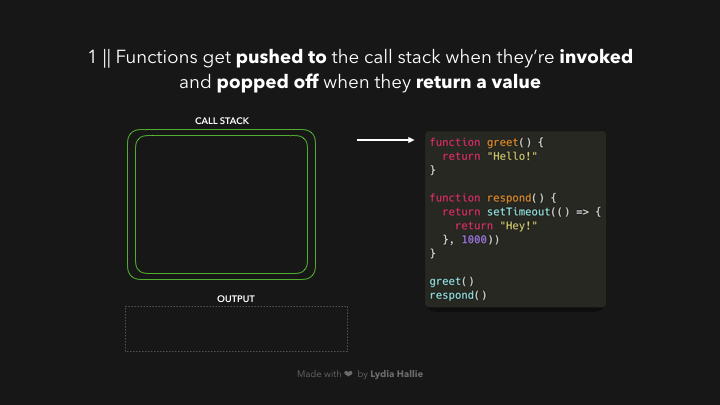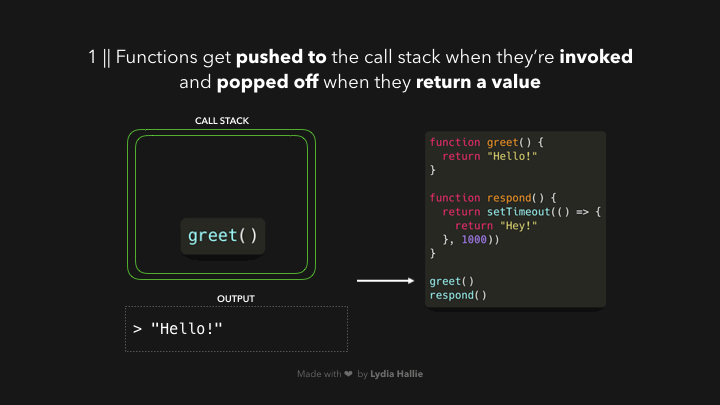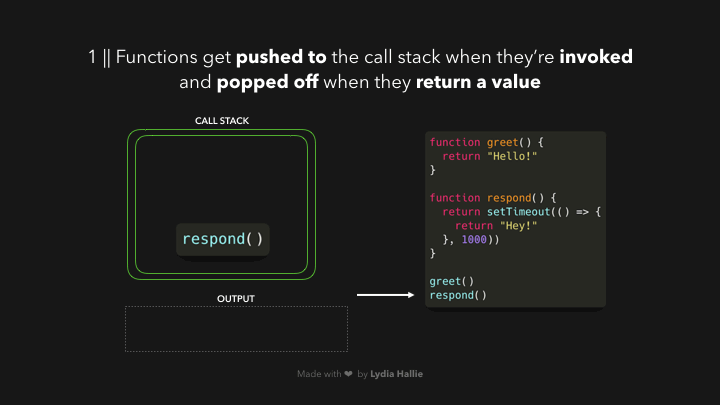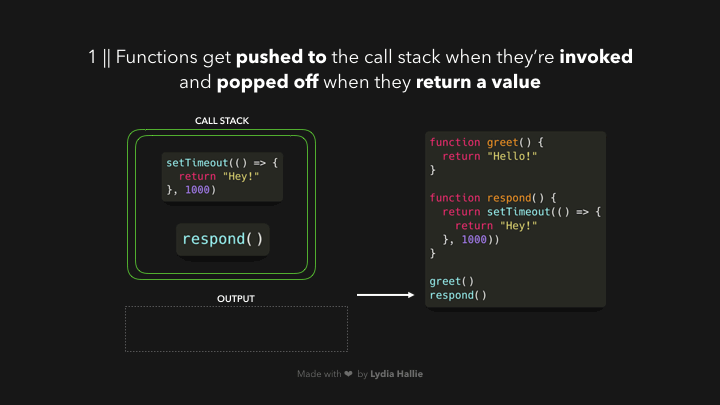
- function ທີ່ຖືກເອີ້ນໃຊ້ຈະຖືກ pushed ເຂົ້າໄປໃນ `call stack`.
- ເຮັດວຽກບາງຢ່າງພາຍໃນ function ແລ້ວ return value.
- ຫຼັງຈາກເຮັດວຽກສຳເລັດ function ນັ້ນຈະຖືກ popped ອອກໄປຈາກ stack.
ຈາກຕົວຢ່າງເຫັນວ່າ `respond` function ມີການ return `setTimeout` function. ເຊິ່ງ `setTimeout` ແມ່ນໄດ້ມາຈາກ Web API — ໃຊ້ໃນການ delay task ໂດຍທີ່ບໍ່ມີການ block main thread. callback function ທີ່ເຮົາ passed ໄປຍັງ `setTimeout` function, ຈະຢູ່ໃນຮູບແບບ arrow function `() => { return ‘Hey’}` ຈະຖືກ added ໄປຍັງ Web API. ໃນຂະນະດຽວກັນ `setTimeout` function ແລະ respond function ຈະຖືກ popped ອອກຈາກ stack ແລະ ທັງ 2 function ຈະ return value ຂອງຕົວເອງ.
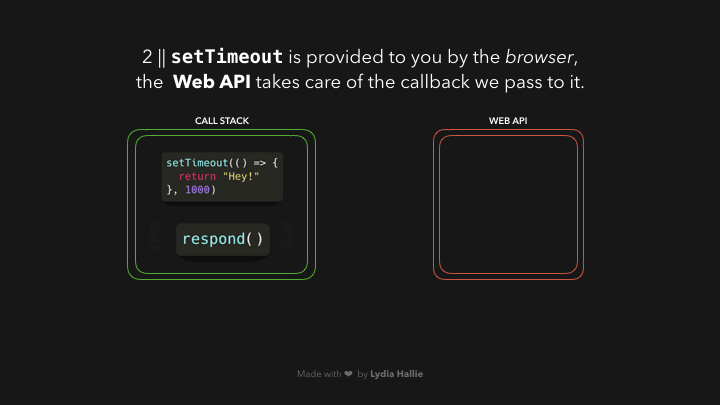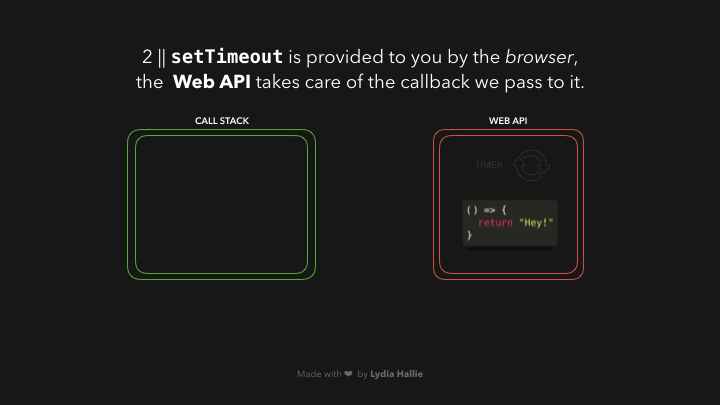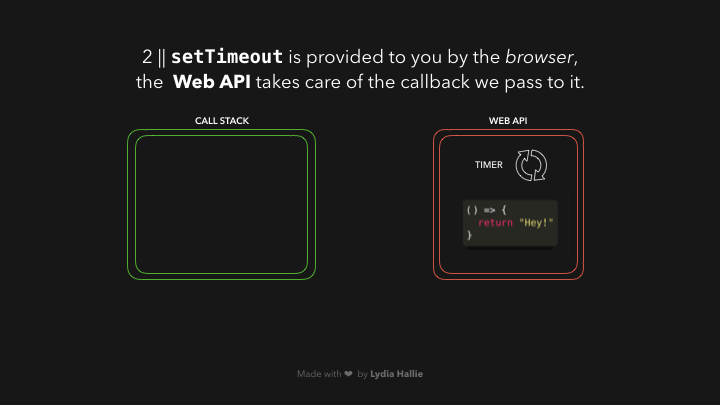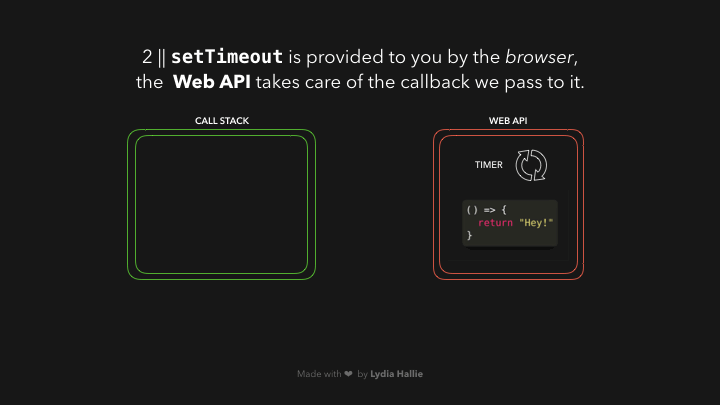
ໃນສ່ວນຂອງ Web API ຈະມີຕົວຈັບເວລາ (timer) ຈະຣັນໄປເລື້ອຍໆຈົນກວ່າຈະຄົບ 1000ms ແລ້ວຈຶ່ງຈະເຮັດສ່ວນຂອງ argument ທີ 2 ທີ່ເຮົາ passed ເຂົ້າໄປ. callback function ຈະຍັງບໍ່ຖືກ added ເຂົ້າໄປໃນ call stack ເທື່ອ, ແຕ່ຈະ passed ເຂົ້າໄປໃນ queue ແທນ.
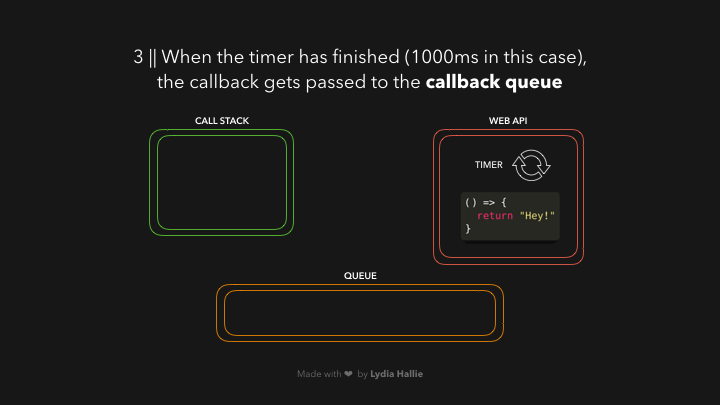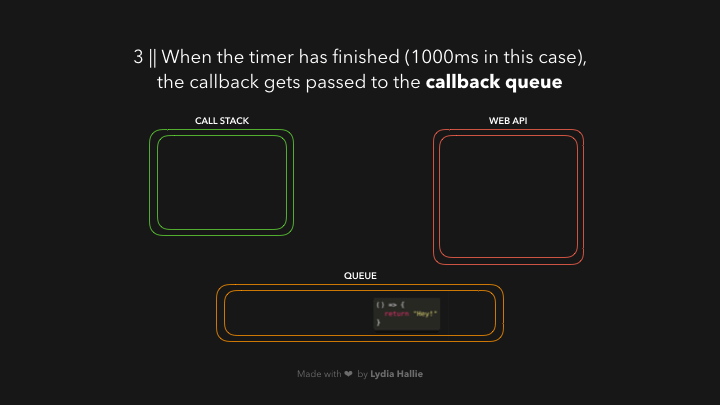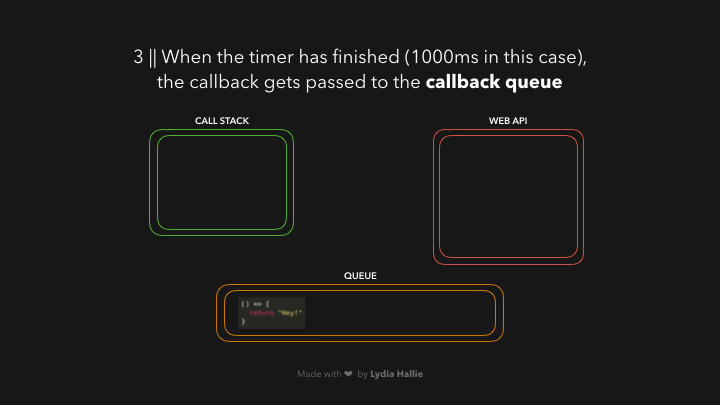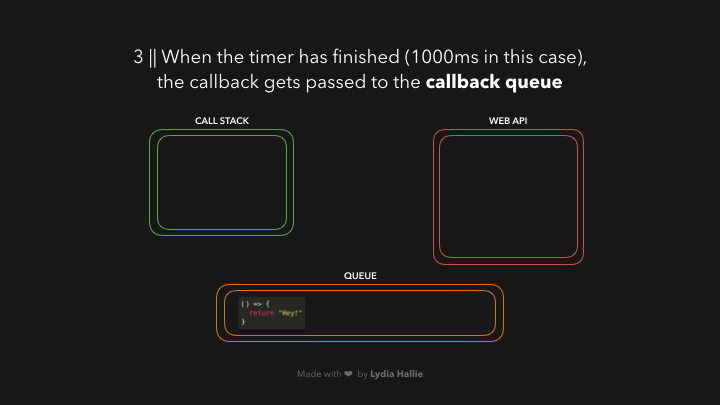
ໃນສ່ວນນີ້ອາດຈະສັບສົນໜ້ອຍໜຶ່ງ, ຈາກຕົວຢ່າງໝາຍຄວາມວ່າ: ຫຼັງຈາກທີ່ timer ເຮັດວຽກໄປຈົນຄົບ 1000ms `callback function` ຂອງເຮົາຈະຖືກ added ເຂົ້າໄປໃນ `queue` ກ່ອນເພື່ອລໍຖ້າໃນການທີ່ຈະຖືກ added ເຂົ້າໄປໃນ `call stack` ອີກເທື່ອໜຶ່ງ 😵💫.
ແລະພະເອກຂອງເຮົາໃນ ep ນີ້ກໍ່ຄື: `event loop` ນີ້ເອງ 😎 — ອັນທີ່ຈິງ `event loop` ມີໜ້າທີພຽງແຕ່ connecting `queue` ກັບ `call stack` ຖ້າ `call stack` ວ່າງຢູ່ (empty) ເທົ່ານັ້ນ🤣🤣🤣. ດັ່ງນັ້ນ ຖ້າຫາກທຸກໆ function ທີ່ຖືກເອີ້ນໃຊ້ (invoked) ໄດ້ return value ຂອງຕົວເອງ ແລະ ຖືກ popped ອອກຈາກ `call stack` ແລ້ວ, item ທຳອິດທີ່ຢູ່ໃນ `queue` ຈະຖືກ added ເຂົ້າມາໃນ `call stack`. ໃນກໍລະນີນີ້ບໍ່ມີ function ອື່ນທີ່ຖືກເອີ້ນໃຊ້, ດັ່ງນັ້ນມັນຈຶ່ງຢິບເອົາ item ທຳອິດທີ່ຢູ່ໃນ `queue` (ໃນນີ້ມີພຽງ 1 item) ແລ້ວ added ເຂົ້າໃນ `call stack`.
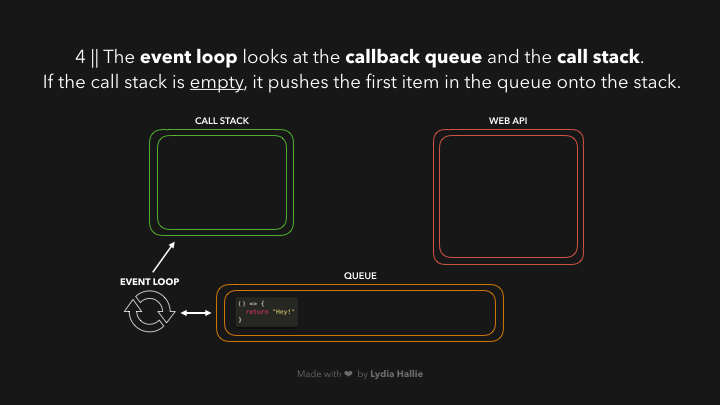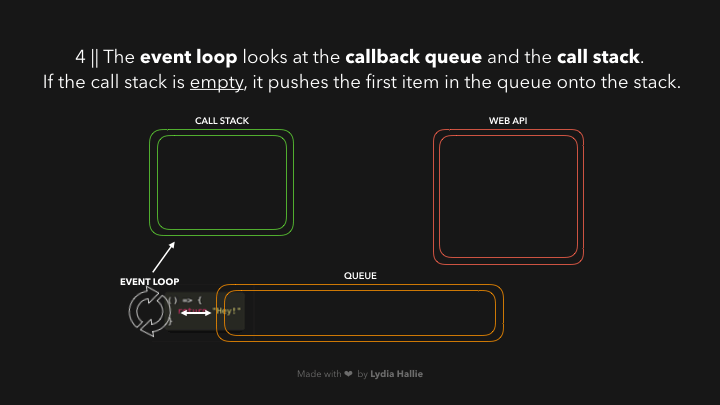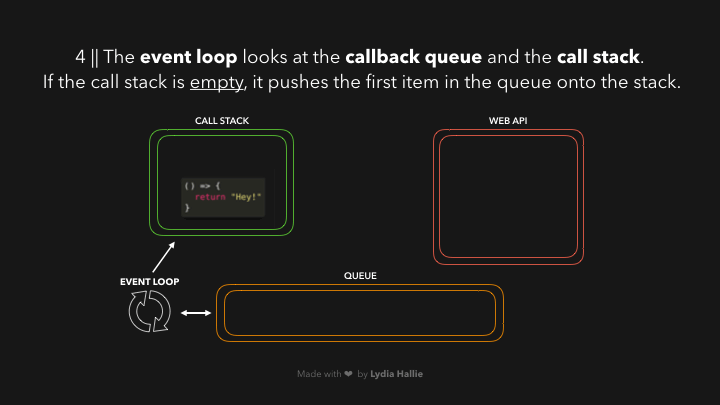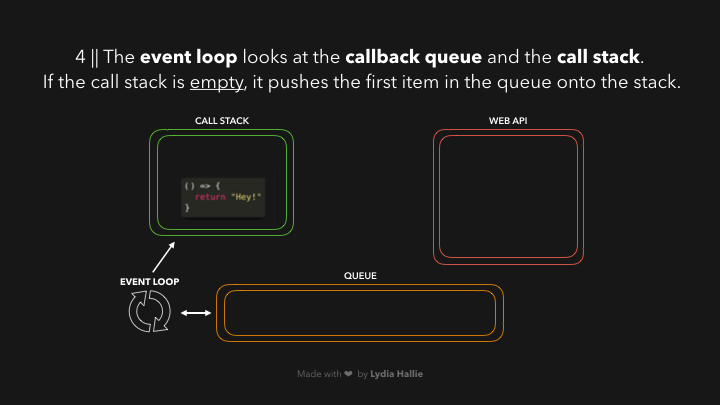
ຂະບວນການໂດຍຫຍໍ້: callback ໄດ້ຖືກ added ເຂົ້າໄປໃນ call stack, ເອີ້ນໃຊ້ (invoked0, return value, popped callback ອອກຈາກ call stack.

ຫຼັງຈາກທີ່ອ່ານຂະບວນການການເຮັດວຽກຂອງ JS ດ້ານເທິງແລ້ວ ເຮົາມາລອງເຝິກສະໝອງດ້ວຍການລອງຄິດພາບການເຮັດວຽກຂອງຂະບວນການດ້ານລຸ່ມເບິ່ງວ່າ function ໃດຈະເຮັດວຽກສຳເລັດກ່ອນກັນ.
const foo = () => console.log("First");
const bar = () => setTimeout(() => console.log("Second"), 500);
const baz = () => console.log("Third");
bar();
foo();
baz();ຈາກ code ດ້ານເທິງຈະມີຂະບວນການດັ່ງນີ້:
ອະທິບາຍ:
- ເຮົາເອີ້ນໃຊ້ (invoked)
barfunction,barຈະ returnsetTimeoutfunction. - callback ທີ່ເຮົາ passed ເຂົ້າໄປໃນ
setTimeoutຈະຖືກ added ເຂົ້າໄປໃນ Web API, ເຊິ່ງsetTimeoutfunction ແລະbarຈະຖືກ popped ອອກຈາກcall stack. - timer ຈະຣັນໄປເລື້ອຍໆ, ໃນຂະນະດຽວກັນ
foofunction ກໍ່ຖືກເອີ້ນໃຊ້ ແລະ logs ຄ່າອອກມາFirst.fooreturn (undefined), baz ຖືກເອີ້ນໃຊ້ ແລະ callback ກໍ່ຖືກ added ເຂົ້າໄປໃນqueue. bazຈະ logs ຄ່າThird.event loopເຫັນວ່າcall stackວ່າງຢູ່ (empty) ຫຼັງຈາກທີ່bazໄດ້ທຳການ return ຄ່າສຳເລັດ. ຫຼັງຈາກທີ່ແຕ່ລະ callback ຖືກ added ເຂົ້າໄປໃນcall stackແລ້ວ.- callback ຈະ logs ຄ່າ
Second
ບ່ອນອ້າງອີງ:
https://dev.to/lydiahallie/javascript-visualized-event-loop-3dif
ຂຽນໂດຍ: phatsss